Graphics CODEx
A collection of (graphics) programming reference documents
The GPU
Overview
The GPU is a complicated beast. We have come a very long way from the old days of doing scanline rendering and just pushing a simple buffer of pixels to the display. As per Blinn’s Law, as computers become computationally more capable, rendering time remains constant. This is because the field of graphics will never stop pushing the boundaries of what is possible.
A GPU can be looked at from a couple of different perspectives.
- How does it work at the logical level
- How does it work at the hardware level1
We will start off by explaining how things work at the logical level, after which we can move to the hardware level.
CPU and GPU
One of the first major things that has to be understood is that the CPU and GPU work very differently. When we write a program, we are mostly writing instructions that will be executed serially2 CPU-side, such as gameplay logic. However, when we want to the GPU to execute something (such as a draw command), we can’t write these instructions directly. Instead we use Graphics API’s to issue these commands which will get executed by the GPU.
Because the CPU is responsible for generating these commands for the GPU, the CPU and GPU run out of sync with each other, with the CPU running ahead of the GPU as it pushes it’s commands into a queue. The GPU then picks up these commands from the queue and execute them when possible. You can kind of see this mechanism as one large async API.
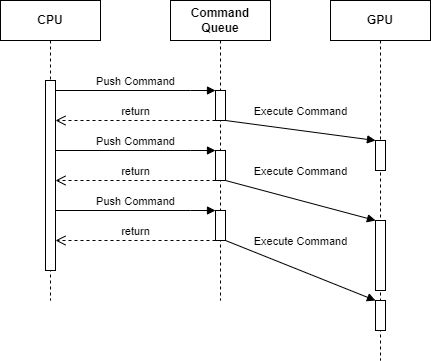
The GPU is always waiting for commands to be executed, either generated by the CPU or the GPU itself. If the GPU is executing and finishing these commands faster than the CPU can generate, resulting in the GPU having to wait for new commands to execute, we say that we are CPU bound.
Meanwhile, the amount of commands that we can have in the queue for the GPU is often limited as well, usually with some form of frame limiting3. If we are pushing commands into the queue faster than the GPU can finish them, resulting in the CPU having to wait for the GPU, we say that we are GPU bound.
Graphics API’s
Unlike CPU side programs, GPU’s do no have a standardised ABI. As a result, generating the commands for a GPU is quite different between the various different IHV’s or even different models from the same IHV. In the early days (think original Doom days), graphics programmers had to write instructions that only worked for specific GPU’s. This of course was quite a nightmare, so an effort was made to try and create some form of abstraction layer for these commands. This is how graphics API’s such as OpenGL and DirectX were created.
The graphics programmer talks to the graphics API and instructs it to e.g. change state, issue a draw command, copy memory between resources, … The graphics API then does a bunch of “higher” level logic on these commands to validate and optimise said commands, at which point it hands these commands over to the graphics driver, which is then responsible for translating these commands to the hardware specific instructions.
Some graphics API’s mimic how hardware works (relatively) closely, such as the more modern Vulkan and DirectX 12 API’s, while older API’s such as OpenGL were created a long time ago resulting in quite obscure abstractions.
Commands & Pipelines
When we push a command to the GPU, we consider these to be one of two types, a command to change state, or a command to invoke work. Examples of state changing commands are changing the bound resources, enabling or disabling alpha blending, etc. while examples of work commands are a draw command, compute dispatch or copy commands.
Each command that invokes work follows a specific path that it takes on the GPU. We call these paths pipelines.
- Draw commands use Graphics pipeline
- Dispatch commands use Compute pipeline
- Copy commands use Copy pipeline
For more information, see the Pipelines chapter.
Threading Model
The GPU is capable of processing huge amounts of data. The only way to manage these large amounts of data is by parallelising the work heavily and trying to avoid latency as much as possible.
Very simply explained, you can think of the GPU being multi-threaded, with each vertex and pixel of a draw call effectively having it’s own thread, resulting in massive amounts of throughput.
In practice, the threading is quite a bit more complicated, as explained in the Threading Model chapter.
Memory
Memory is quite a complicated subject, with each graphics API dealing with it in quite a different way. As a result, this has been split off into a separate chapter, see the Memory chapter.
-
How the hardware works is very different between different platforms and IHV’s, but a lot of general principles apply. ↩
-
Ignoring multi-threading and various CPU optimisations such as out-of-order execution or speculative execution. ↩
-
We often set a limit of how many frames of commands we can queue up before we consider ourselves running ahead too much. There are many different reasons as to why we do this, from performance to game feel due to latency. ↩
Last modified on Monday 31 January 2022 at 16:04:45