Graphics CODEx
A collection of (graphics) programming reference documents
Threading Model
- Overview
- SIMT
- Warps and Wave(front)s
- Compute Units and Streaming Multiprocessors
- Fixed vs Variable Latency
- Latency Hiding
- Occupancy
Before reading this chapter, please read the SIMD chapter first.
Overview
Often when you read about how a GPU works, you’ll be told that it has a huge amount of cores and as a result can execute many instructions at the same time for large amounts of data. This description is only half correct. A GPU achieves high throughput parallelism in quite a different way than a CPU, as it’s main goal is to operate on large amounts of data (e.g. vertices and pixels), not a large amount of instructions.
SIMT
Modern GPU’s achieve their high amounts of parallelism through a technique called SIMT. SIMT stands for Single Instruction Multiple Threads and is very similar to SIMD, but has a different mental model. Instead of seeing the separate slots in the registers as e.g. components of a vector, we instead see each slot in a register as a value for a different thread.
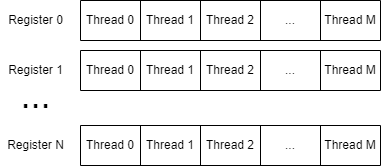
In order to achieve this, the GPU deconstructs all vector operations to be per-component, similar to a scalar architecture, but instead of executing the instructions for only a single value, it executes the instruction for all values of all of the threads by executing on an entire register1.
One large side-effect of this is that all of the threads execute in lock-step, as the instructions get executed for all threads at the same time. This is quite different from a CPU, where each thread operates independently from another by using a different core.
Warps and Wave(front)s
Now we talked about how all operations occur on the values of all threads at the same time through the use of registers and SIMD. However, we also know that the GPU can kick off a humongous amount of threads. For example in a draw call, it will kick off a single thread per vertex. If we are drawing a model with 300’000 vertices, that’s a lot of threads. If we would want to support the register usage for that, we would need 9MiB per register. With shaders often using ~30 registers or more, that would be 270MiB for the registers for one shader alone. This is of course not feasible.
Instead, the GPU splits up all of the various threads that have to be executed by a command (e.g. draw call) into groups of a fixed size. For example, GCN hardware uses group sizes of 64 threads per group, while NVIDIA hardware uses 32 threads per group. These groups have different names across all of the various IHV’s but will often be colloquially referred to as warps (NVIDIA, Intel) or wave(front)s (AMD). For the remainder of these pages I will continue to use the term wave.
Each one of these waves will operate independently of each other (sort of) and will have it’s own program counter and state associated with it. This means that for vertices and pixels, they are processed in batches the size of these waves, for instance 64 on GCN.
Compute Units and Streaming Multiprocessors
Now that we have these threads split up into manageable batches of fixed size, we need something to execute them. On the CPU, each core can process a single thread at a time with the scheduler assigning threads to specific cores or yields them if they are e.g. waiting, ready for another thread to be scheduled. On the GPU, we use a similar principle, but instead of scheduling one thread at a time, we schedule one wave at a time per core. This means that these cores are quite a bit more complex, as they are operating on a larger amount of threads through these registers at a time. As is tradition, these GPU cores have got different names across all IHV’s, with AMD often referring to them as compute units, while NVIDIA refers to them as streaming multiprocessors. In theme, I will stick to AMD naming and refer to them as compute units for the remainder of these pages.
Fixed vs Variable Latency
Before we can continue, we need to take a small detour to explain fixed vs variable latency instructions. All instructions in a shader can have dependencies on a previously calculated value. When a new instruction is issued, we need to ensure that the results of the previous calculation are ready to be used as input to the new instruction.
When a shader is compiled into it’s lowest-level instruction set (ISA), each instruction takes a certain amount of cycles. Some instructions always take the same amount of cycles, such as floating-point multiplication or addition. These instructions are called fixed latency instructions. When the compiler has compiled this shader, it can manage the instruction dependencies by scheduling different instructions in between since it knows how long this instruction took.
Other instructions, such as instructions that access memory (e.g. sampling from a texture) do not have a predetermined amount of cycles to complete. These are called variable latency instructions. Because of the fact that the compiler can’t know how long it will take for this instruction to complete, if any instruction later in the shader is dependent on a variable latency instruction, it needs to insert an explicit instruction to wait for the previous result to complete. This will idle the wave waiting until the variable latency instruction has completed, at which point it will continue execution.
Latency Hiding
When we say that a single wave is scheduled to a compute unit, this is actually a lie. In practice, each compute unit can have multiple waves scheduled on it at a time. For instance on GCN, each compute unit has a theoretical maximum of 10 waves at a time. Each cycle, a compute unit executes an instruction for a single wave. However, a wave can stall, usually by issuing a wait instruction on a variable latency instruction. Instead of idling the entire compute unit, it will instead choose a different wave to execute an instruction from next cycle. This technique is called latency hiding.
Occupancy
A compute unit will not always have the theoretical maximum amount of waves scheduled. As a compute unit’s resources (such as the register file) is fixed size, if a shader requires too many resources per wave, such as the amount of registers used, it will not be able to schedule the maximum amount of waves on the compute unit. The amount of waves that is possible to be scheduled per compute unit for a specific shader is called the occupancy. If the occupancy of a shader is too low and a wave is stalled (e.g. waiting for variable latency instruction), it will have a smaller pool of waves to choose from to execute instead which will result in a longer execution time.
-
Not all hardware can execute on all values in a register in a single cycle. For example, GCN holds 64 values in a register, but can only execute on 16 at a time, resulting in an instruction taking at least 4 cycles. ↩
Last modified on Wednesday 02 February 2022 at 11:42:03